As SQL Server is coming to the Linux platform, there’s going to be a bunch of new commands within the OS that you’re going to need to know so that you can properly move around the Linux operating system.
Connecting
Let’s start with the basics, there’s no remote desktop (RDP) into most Linux systems (there are options out there for setting up RDP on Linux but you probably don’t want it on your production Linux servers as ssh is all you should need). Because there’s no remote desktop available you’ll need to use Putty to ssh into the server. Putty is basically like a telnet client that supports all manor of connection options including telnet, ssh, rlogin and direct serial port connections. 99.9% of the time all you’ll care about is ssh.
If you need to get files on and off of the server then you’ll want to have WinSCP. WinSCP is kind of like an FTP program, but it uses ssh instead of FTP to move the files up and down to the server.
“Run As”
When you log into a Linux server you don’t have admin rights to the server. You’ll need to use a command called sudo to run commands as the root login. Normally you’ll just need to run a few commands as root so you’ll just put sudo in front of the command.
sudo someCommand -someParameter
Directory Listings
Linux has directories, in the windows world we either call them directories or folders. They are basically the same thing. To see what’s inside of a folder you can either use the dir command or the ls command. The output of these commands 
will be slightly different as you can see here. The output from dir is all basic text while the output from ls is color coded to mean different things. Both dir and ls support the –help (there’s two dashes there) flag which will output all the various switches which are available for those commands. Normally when I’m working in Linux I switch to ls, mostly because I have the switches that I need memorized. The one that I probably use the most is ls -l as that gives me everything in the directory along with all the attributes of the file (read, write, execute, owner, size and date) that I normally care about seeing.
Changing Directories
Changing directories is done using the cd command just like in windows.
Free Disk Space
Checking for free drive space in Linux is done via the df command. This will output by default the number of blocks on the partition, the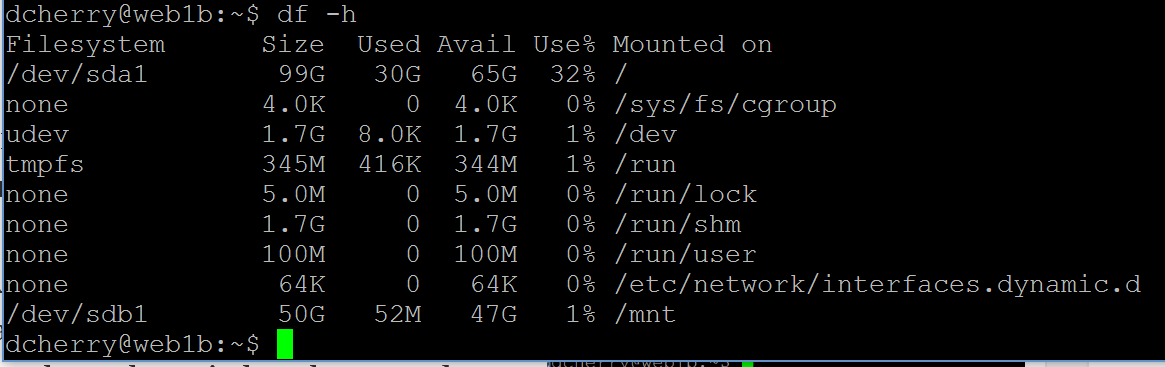 number used and the number available. Now at this point you have to do some math to figure out how much space you actually have. The easier way is to use one of a couple of switches to get the output in a more useful format. If you use df -h you’ll get the output in Gigs (or Megs, or KB) instead of blocks. This makes it MUCH easier to figure out what’s going on. Not only does df give you the size of the partition, but it tells you the percentage of free space on the partition.
number used and the number available. Now at this point you have to do some math to figure out how much space you actually have. The easier way is to use one of a couple of switches to get the output in a more useful format. If you use df -h you’ll get the output in Gigs (or Megs, or KB) instead of blocks. This makes it MUCH easier to figure out what’s going on. Not only does df give you the size of the partition, but it tells you the percentage of free space on the partition.
Running Processes
There’s a few different ways to see what’s running on a server. The first is ps. This will give you a list of processes running on the server under your session. ps -all will give you a list of all the processes running on the server, including background processes. It doesn’t give you all that much useful information about the processes, just the time the process has taken on the CPU, the pid and the process name.
If you want a lot more useful information about what’s running then you’ll want to run top. top gives you a variety of information about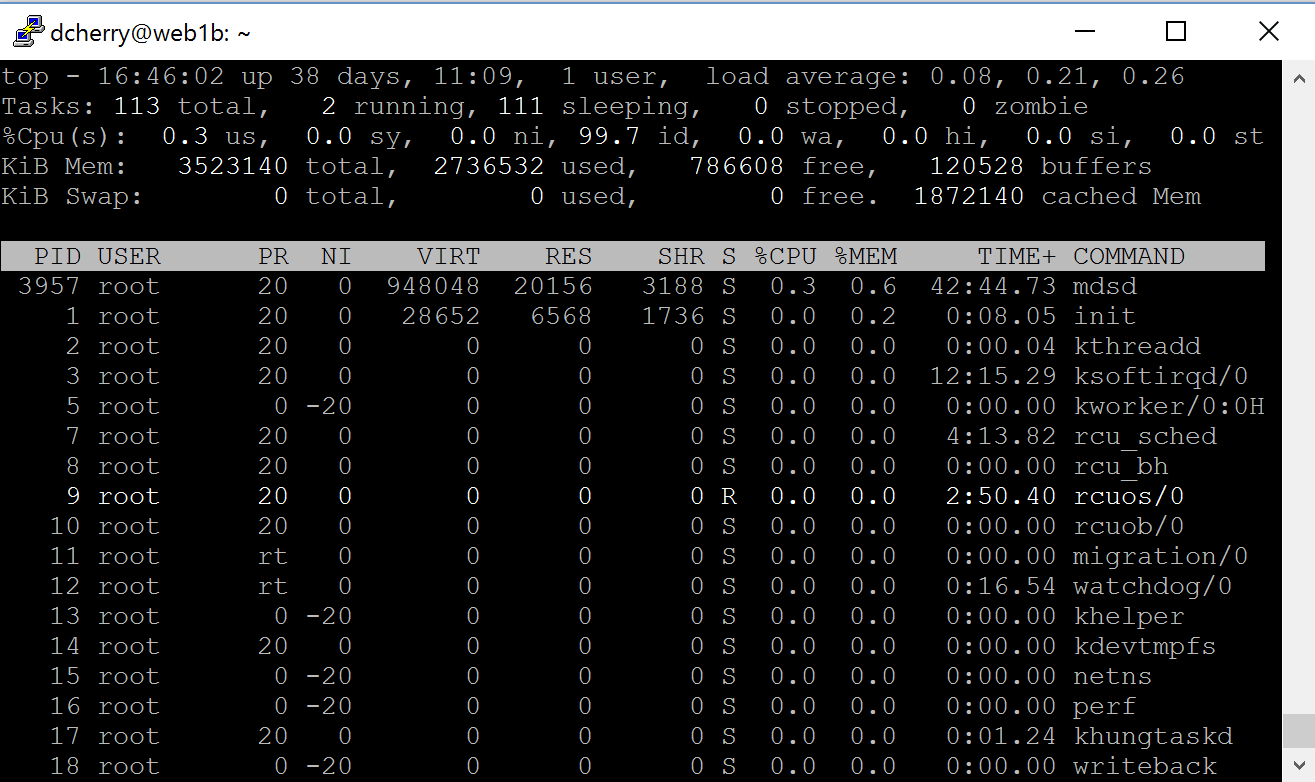 what’s running within the machine such as the CPU, uptime, number of processes, memory in use and a wealth of information about each process. While ps is just a dump of information to the screen, top is a real time feed of data and it updates every couple of seconds to give you fresh information. If you press the ? key then you’ll get a help screen with will give you a bunch more information about the processes that are running on the system. This includes being able to change the columns which are displayed, do filtering and sorting,
what’s running within the machine such as the CPU, uptime, number of processes, memory in use and a wealth of information about each process. While ps is just a dump of information to the screen, top is a real time feed of data and it updates every couple of seconds to give you fresh information. If you press the ? key then you’ll get a help screen with will give you a bunch more information about the processes that are running on the system. This includes being able to change the columns which are displayed, do filtering and sorting,
Editing Files
Editing text files is where things start getting really complicated. There’s a few text editors out there for Linux and they are all “interesting”. Personally I use vi, mostly because I hate myself. vi is a great text editor that’s VERY powerful, but you have to have all sorts of internal switches memorized to use it. Now I’ve been using it since I first started playing with *nix 15+ years ago so I’m pretty used to it. To edit a file with it, just run vi with the filename after it.
vi myfile.txt
That will open the file in VI and let you edit it. Now vi has two modes, command mode and insert mode. By default you are in command mode. This lets you run all sorts of commands over the file such as search, etc. When in command mode if you type a : it’ll show up at the bottom of the screen. For example if you wanted to search for a text string while in command mode you’ll type :/SearchString/ and press enter. vi will then take you to the next line that has that string on it. If you want to do a search and replace on the file and replace the next occurrence of the text then you’d use :s/SearchString/ReplaceString. You can probably start to see why I said that I hate myself for using vi.
To get into insert mode so that you can type and delete press the letter “a” on the keyboard. This will put you into insert mode and you can now change things, navigate with your arrow keys, delete characters, etc. To get back into command mode press the escape key.
If you need to delete a entire line from a text file go into command mode by pressing the escape key then hit the d key twice. That’ll delete the entire line.
If you want to save the file go into command mode and type :w and press enter. That’ll save the file without closing it. To save and close type :q and press enter. To save without closing type :q! and press enter.
While using vi you’ll want to avoid the number pad for typing numbers. Trust me.
One of the things I really like about vi is that I can tell vi to take me to a specific point in the file. If I know the line number I need to get to, running vi +nn filename will cause vi to open the file and go directly to that line number.
There’s a variety of other text editors out there such as pico, and emacs as well. I’ve just never liked them as much as vi.
Job Scheduling
If you need to schedule things to run in Windows you’d use Task Scheduler. We don’t have Task Scheduler in Linux, we have cron instead. Cron is edited by using the crontab -e command which opens up a text editor. The first time you run crontab it’ll ask you what editor you want to use. Most people use emacs and that’s what you’ll see most of the demos use.
Once in the editor scroll to the bottom of the file. That’s where you can specify new tasks to run. The format of the line is pretty annoying. There’s 5 values which you specify to control when the job should run. These are space delimited and are:
- Minute
- Hour
- Day of Month
- Month
- Day of Week
If you want the job to run on any possible value for these fields then use an * for that position. After those five fields you specify the command and any parameters that you want to run. Lets look at some examples, all of which are going to run the command /var/myCommand.
Run daily at midnight
0 0 * * * /var/myCommand
Run at 5am
0 5 * * * /var/myCommand
Run Sunday at midnight
0 0 * * 7 /var/myCommand
(You can use 7 or 0 to represent Sunday. This is for legacy support as is the old days some systems supported 0 and others supported 7.)
Run Every 5 Minutes
*/5 * * * /var/myCommand
Run Every Other Day
* * */2 * * /var/myCommand
Run at Midnight on New Years
0 0 1 1 * /var/myCommand
As you can see this is a pretty powerful way of scheduling commands.
That should give you a pretty good understanding of the basic Linux commands that you’ll need to work with files within the Linux operating system while putting SQL Server database instances on Linux.
Denny
The post Linux Commands You Need To Know appeared first on SQL Server with Mr. Denny.