In recent years, we’ve seen an upturn in adoption of the open-source database engine PostgreSQL. Commercial databases like Oracle and SQL Server can become quite expensive as applications grow to massive scale. Oracle licensing is complex and very expensive. While we at DCAC still love SQL Server and it’s at the heart of our business, we do see the demand for PostgreSQL cropping up amongst clients. PostgreSQL is a solid database engine—I’ve built applications on it, however as economist Milton Friedman famously said, “there is no such thing as a free lunch.”
If you talk to any database expert, you’ll know PostgreSQL has a couple of limitations that can make scaling challenging. Lack of an execution plan cache is one, the IO-intensive vacuum process are the most common challenges to building enterprise apps on PostgreSQL. However, those limitations mostly only impact higher throughput workloads. I wanted to bring up a topic that impacts everyone trying to manage a PostgreSQL database—backups and high availability/disaster recovery (HA/DR).
While PostgreSQL has a mature database and storage engine, backup and restore has always when been somewhat problematic. The backup process simply takes a logical dump of the database. You can think of this like a series of data-definition language (DDL) like CREATE TABLE, VIEW, etc, followed by data manipulation language (DML), which loads the data. There are also backups of the write-ahead log (WAL), which can be applied to do point-in-time recovery. The problem with this structure isn’t data security—it’s performance. When a restore has to be a written to the transaction log, it’s always going to take far longer than an OS level restore, which effectively copies files at the speed of IO (the way Oracle and SQL Server restore works).
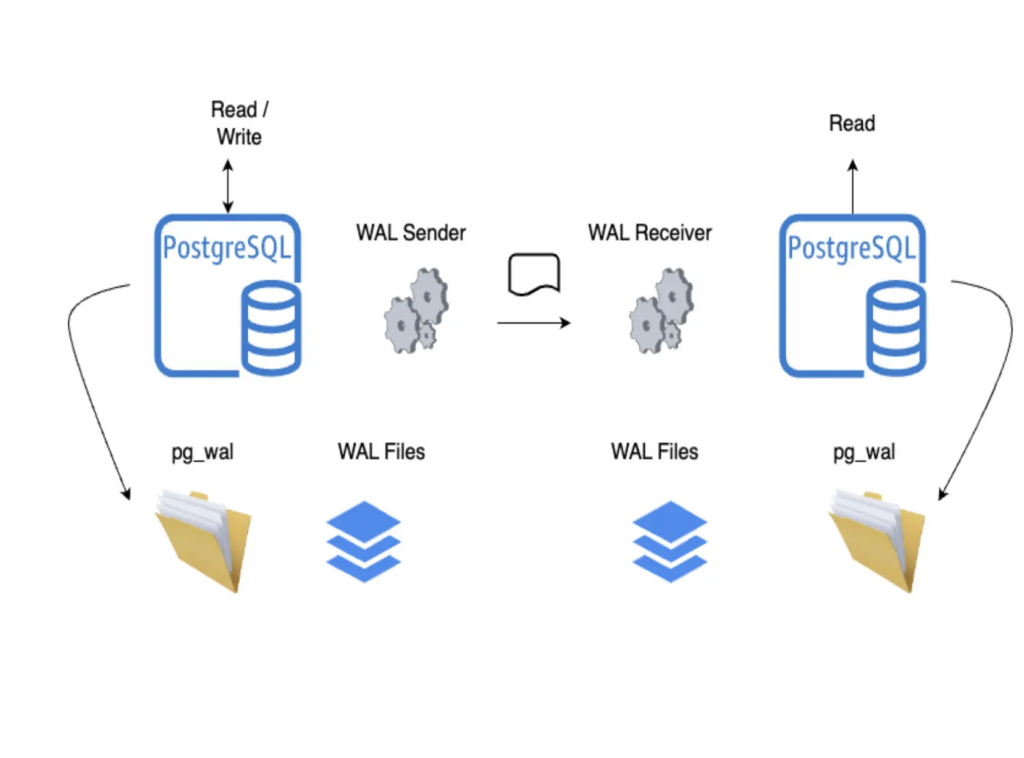
While this limitation makes backup in PostgreSQL (MySQL also has a similar backup model), there are workarounds. PostgreSQL’s extensibility has provided several vendors “better ways” to do backup, but those incur licensing costs. Cloud and storage providers, like Pure Storage both provide snapshot based backup and restore, which make the process a lot faster. In our experience, customers that move to PostgreSQL don’t’ want to spend money on licenses, so our typical recommendation is to use a cloud provider for those databases.
The other challenging aspect of PostgreSQL is high availability and disaster recovery. The methodology PostgreSQL uses to protect data is fine—it’s the functional equivalent of availability groups or log shipping in SQL Server, with a few less frills. However, there’s one really big problem—clustering on Linux is a terrible mishmash of open-source tools and packages. This is probably the biggest factor that has limited SQL Server on Linux, and yeah, it affects PostgreSQL a lot too.
I’ve built clusters for clients using Pacemaker, HA-Proxy, and the couple of other packages required to make clustering work. All my clients have struggled to actually use those clusters. I’ve had one or two customers who were willing to run PostgreSQL on Windows (yes, I know this is heresy) and while it takes some solid knowledge of Windows Server Failover Clustering to build a HA Postgres solution, once built, it works robustly and reliably.
Database licensing can seem really expensive, especially if you use Oracle. However, one of the major benefits vendors like Microsoft provide is an easily deployed, robust solution that’s highly available. If you choose to go with an open-source DB like PostgreSQL, know that some of the basics will be more challenging, or that you may want to stick with cloud solutions. At DCAC, we can help you both do the math on your cost savings, and help you build robust solutions, no matter what database engine you choose.