Public clouds like Azure, AWS, and Google Cloud Platform, have always been an attractive disaster recovery target, especially for small to medium sized business. While large enterprises will have multiple data centers deployed across multiple geographies as a standard course of their business, many smaller firms operate out of co-location facilities and typically have personnel located in a more limited geography. However, the public cloud with its multiple regions, availability zones open enterprise availability architectures to organizations of any size. However, there are a few caveats—let’s talk about HA/DR in the cloud and what you should look out for.
Editor’s Note: This was written before last Friday’s complete outage of Azure East US. Cloud failures are frequently regional in nature—you’re mission critical apps should be multi-region if they are very important to your business’s operations.
Let’s talk about the building blocks of the public cloud—these concepts are mostly universal across the three cloud vendors, but we’ll call out where they are different.
Regions: Region are geographical collections of cloud resources. They are nearly always made up of multiple data centers. Data within a region doesn’t leave a region unless you have specified that it does. Regions are grouped into geographies which enforce geopolitical boundaries. Regions are hundreds of miles or kilometers away from other regions (one Azure exception in Australia where two regions are in close proximty) to aim for protection against natural disasters, and there is no guarantee of network latency between regions. This means any data movement between regions should be asynchronous.
Availability Zones: We mentioned that regions contain multiple data centers. In most cases the data centers are grouped into “Availability Zones”. Data centers in an availability zone use different power and networking providers from each other to avoid single points of failure, however the data centers are close to each other—typically within 100 km/62 miles. Microsoft mentions a sub-2 millisecond round trip latency between AZs, which means it can be used for some synchronous highly available workloads.
Availability Sets: Availability sets are a construct unique to Microsoft Azure. In the early days of Azure there was no availability zone configuration available, and availability sets are a way to ensure groups workloads like SQL Server Availability Group nodes are in different server racks, and don’t share common storage.
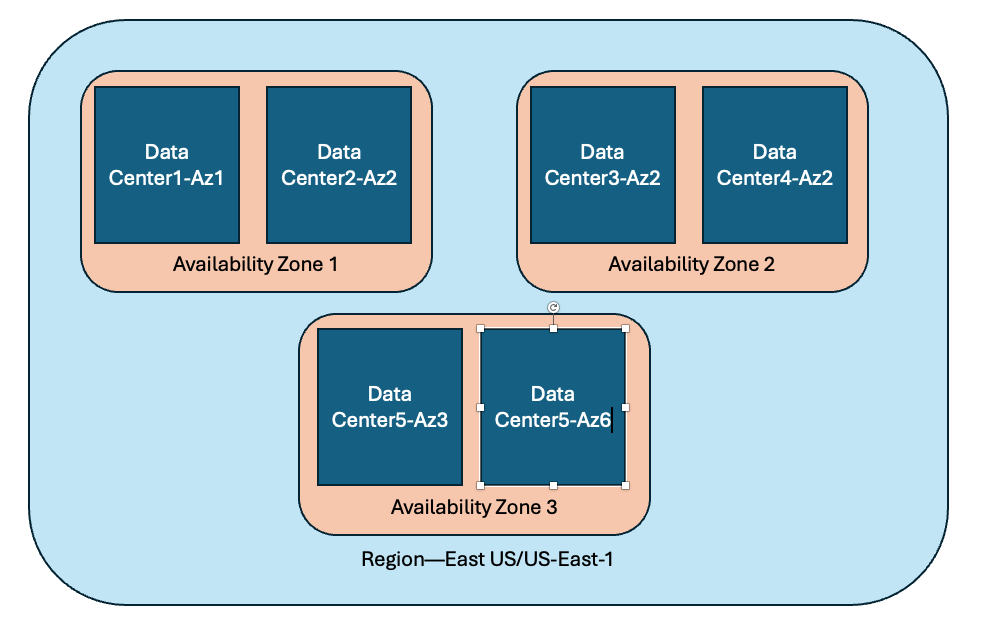
Figure 1 Architecture of Regions, Data Centers, and Availability Zones
All these constructs allow you to build highly available workloads in your cloud provider. Most of the customers we’ve worked with are content with building solutions in a single region, spanning across availability zones. However, most cloud outages are regional in nature, which makes cross-region disaster recovery a better option for mission critical applications. However, it can be complex to manage the networking, DNS, and program code for cross-region applications.
Uptime isn’t the only thing you have to worry about in the cloud these days. One of the biggest challenges is finding capacity, while the cloud providers have collectively been spending hundreds of billions of dollars per year on AI, they haven’t been making the same investments in their “standard” cloud capacity. This means that while you may have great notions of highly available architecture, you may be unable to deploy it, or have to spend excess money on “capacity reservations” that guarantee your compute is available when you failover.
One other thing that’s important to understand are what services are global in nature, and which services have single points of failure (that latter can be harder to identify). A couple of recent outrage examples are Azure Front Door, which is a global load balancing and content delivery network (CDN) service going down globally, and an AWS outage in US-East-1 blocking DNS updates from happening globally.
Making availability decisions is always complex—and isn’t just a technical problem. Your business needs to understand the real cost of downtime, and understand the risks for any given design. At the same time, adding availability can come with great cost, and can be seen as wasted spending. At DCAC, we can help you understand your HA/DR needs and build optimized solutions to help your company keep the lights on, while balancing the budget.