It’s amazing just how much difference having a non-clustered index on the child table of a foreign key can matter when the foreign keys have cascading deletes turned on. In the example that I’m thinking of a new table was added when the application was upgraded the week before. Then Monday morning there were all sorts of blocking and deadlock problems when trying to delete data from a large table with 2.4B rows in it. The problem table wasn’t the big table, but instead the new table with all of 455k rows in it when I looked at it.
Looking at the execution plan for the stored procedure which does data deletion from the large table and the problem become painfully clear. There was a clustered index scan on the new table for each row which was deleted. That clustered index scan was part of the deletion transaction so anyone trying to insert into that little table was being blocked. So basically a nice chain reaction was happening.
This was easily shown in the CPU workload as well shown below. You can see the CPU workload on the system spike to above 40% to almost 50%, which is a lot on a system which has 80 logical CPUs and normally runs at about 11% CPU workload.
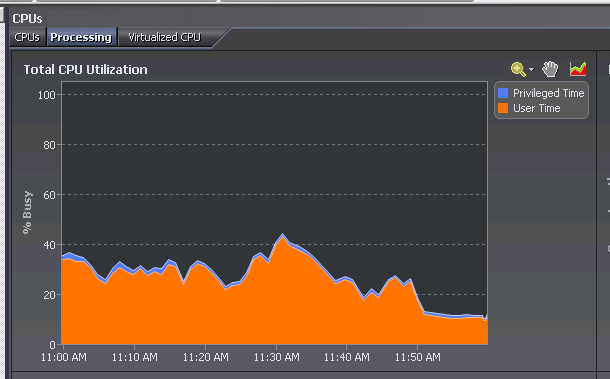
In the graphic you can see exactly there I added the indexes as the workload drops right at 11:50AM.
This just goes to show that if you plan on using foreign keys to handle data deletion between tables you need to ensure that the column which is the child tables foreign key has an index on it.