You might have noticed that I titled this post Part II, but with no “of N”. This will likely be a periodically recurring series of posts as I take things a bit further with Kubernetes. Also, likely I will be correcting things I screwed up along the way. The first of which is that I said if you had a Mac this is easy to configure using the Docker Edge configuration with Kubernetes. Well it was easy to configure K8s with Docker–however when I got deep into playing with SQL Server, I kept running into weird issues with storage persistence and instance startup. I was chatting with a colleague on the product team (thanks Mihaela!!) and she told me about this bug:
https://github.com/Microsoft/mssql-docker/issues/12
It’s complicated–but basically the Docker filesystem mapper isn’t consistent with SQL Server’s I/O code. So, in lieu of that, I installed Minikube on an Ubuntu VM on my Mac. You can find the instructions here, you will have to install VirtualBox to host the VM for your Kubernetes install. It was really straightforward–if you want to build a “real” Kubernetes cluster, the process is a little bit more complicated, and outside of the scope of today’s post.
What are We Building?
In January, the SQL Server Product Group posted this blog post on deploying SQL Server in a high-availability configuration on Kubernetes. It went without much fanfare, but I dug into the post, and built the solution, and realized it offers nearly the same functionality as a Failover Cluster Instance, with minimal configuration effort. While building an FCI on Windows is quite approachable, building an FCI on Linux is somewhere between painful and awful, depending on the distribution you are using, the day of the week, and the position of the stars. The post assumes you are building on top of the Azure Kubernetes Service–which is a great way to get started, but it costs money, and I wanted to do something in a VM. So we’re building the same basic architecture that is in that PG post, however we are going to build it on minikube.
Components
There are a couple of things we are building here:
Persisted Disk: Inherently containers have no persisted storage. Obviously, this is a problem for database containers. We are going to define a persistent volume claim to map our storage account. This is probably the biggest difference between my code and the PG blog post, as I’m referring to local storage as opposed to Azure disks.
Deployment: This refers to our container and volume. You will see this defined in the code below.
Service: We are defining a service and creating a load balancer for our deployment. The load balancer is the key to this deployment, as it will maintain a persistent IP for our deployment when our container goes away.
By defining this deployment in this way, if we have a failure on a host that is hosting our container, Kubernetes auto-healing process will automatically deploy a new pod (in the context here, a pod just holds our single container, a web server might have multiple containers in the pod.
Let’s Build Something
This assumes that you have minikube up and running. The first thing you’re going to do is build a secret to pass into your deployment, for your SA password.
kubectl create secret generic mssql --from-literal=SA_PASSWORD="MyC0m9l&xP@ssw0rd"
The next thing you are going to do is build you persistent volume claim.
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: mssql-data-claim spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi
You will save this text in a file. For the purposes of this posts, we will call it pv-claim.yaml. You will then run the kubectl apply -f pv-claim.yaml command. You will see the message “persistentvolumeclaim “mssql-data-claim” created
Next we are going to build our deployment and our load balancer.
apiVersion: v1 kind: Service metadata: name: mssql-deployment spec: selector: app: mssql ports: - protocol: TCP port: 1433 targetPort: 1433 type: LoadBalancer --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: mssql-deployment spec: replicas: 1 template: metadata: labels: app: mssql spec: terminationGracePeriodSeconds: 10 containers: - name: mssql image: microsoft/mssql-server-linux ports: - containerPort: 1433 env: - name: ACCEPT_EULA value: "Y" - name: SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: SA_PASSWORD volumeMounts: - name: mssql-persistent-storage mountPath: /var/opt/mssql volumes: - name: mssql-persistent-storage persistentVolumeClaim: claimName: mssql-data-claim
There’s a lot of stuff here. Let’s walk through the key elements of this file:
We’re defining our service and load balancer at the beginning of the code. Next, we are defining our deployment, which specifies the container we’re going to use, which in this case it is the latest release of SQL Server 2017, and it picks up our predefined SA password. Finally, we are defining our volume mount and its path for where it will be mounted in the VM. Save this off to a file called sqldeployment.yaml. You will run the same kubectl apply -f sqldeployment.yaml to deploy this. You will see service “mssql-deployment” created and deployment “mssql-deployment” created. You can verify the deployments by running the below commands:

You’ll make note of that IP address and port for your SQL deployment. You do need to make note of that port, however, that IP address is not routable within that cluster. There is some weirdness here to running minikube. I’d like to thank the Database Avenger for this post which showed me how to connect to the kube. Run the following command, which will give the IP address to connect to:
minikube service mssql-deployment --url
Your output will give you the IP address and port you can connect to.
Can We Login Yet?
So, I have SQLCMD installed on my Linux VM (instructions for SQL tools for Linux). If you have made it this far, this is just a standard SQL connection (albeit to a non-standard port, which is denoted by a comma after the IP address)
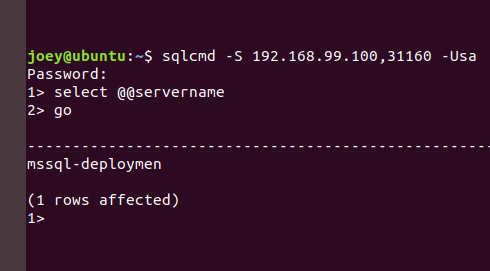
You can see my server name is mssql-deployment. I’m already out of space, so come back next week to talk about persisting data, and how failover works.