Anyone who has had to manage a large SQL Server replication environment has had to deal with strange locking within the distribution database. This is because the distribution database is basically a giant named value pair database which has a TON of jobs inserting, updating, querying and deleting huge amounts of data from the database.
Within a SQL Server Distribution server there’s a few different things that you need to watch. There’s the log readers which are inserting new data into the distribution database. There’s the distribution agents which are querying rows, and updating rows in the distribution database, and there are clean up jobs which are deleting rows which have been replicated to all the needed subscribers.
One of clean up jobs, called the “Distribution clean up: distribution” job likes to take large locks on the distribution tables while it’s trying to delete data. In a smaller environment you probably won’t notice this all that much because your replication tables are pretty small so the data is deleted pretty quickly. Looking at the Space Used by Top Tables report in SQL Server Management Studio, we can see that this replication topology isn’t all that small.
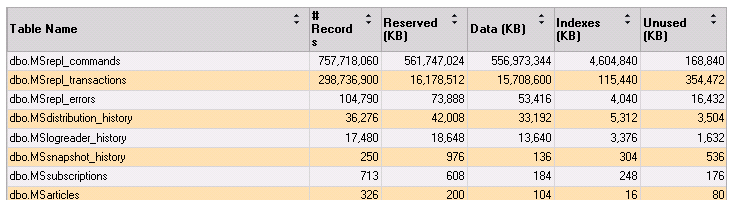
Yes, that says that there are 757M commands to be replicated across 300M transactions. In other words, there’s a lot of stuff that needs to be replicated.
When looking at this system recently I noticed that several of the log reader jobs were in an error state because they hadn’t been able to report in for at least 10 minutes, and some of them where in this state for quite a while. Looking at the output from sp_whoisactive the reason became very clear quickly, there was blocking going on in the distribution database, and the log reader jobs were being blocked. Looking into who was doing the blocking, and I saw that it was a delete statement. Looking at the list of running SQL Agent jobs on the server that are clean up jobs (as these are the only ones which should be deleting data) I see that the distribution clean up job is running. All this job does is run a stored procedure, which makes it nice and easy to see what it’s doing.
Reading through the stored procedure, I dived though a couple of additional stored procedures until I found sp_MSdelete_publisherdb_trans which is the one which does the actual deletion of the data from the distribution database. Reading through the stored procedure I ran across the actual DELETE statements from the MSrepl_commands table. And these delete statements all have a WITH (PAGELOCK) hint on them, which I assume is to prevent the DELETE statement from escalating to a table lock and locking the entire table. When unfortunately when you’ve got a lot of different systems writing data into the MSrepl_commands table like this system does (there are 47 publications on this distribution server) there can be data from different publications all stored on the same page.
My solution to solve this probably isn’t something that Microsoft would be all that happy about, but keeping them happy isn’t really my big worry. I changed with PAGELOCK hints to ROWLOCK. While this does of course require more locks to be taken, I’m OK with that overhead, especially as the DELETE statements all have a TOP (2000) on them. I made the same change to the sp_MSdelete_dodelete procedure as well to ensure that it doesn’t do any additional bad locking which I don’t want on the MSrepl_transactions table.
So if you have a large replication topology with lots of data flying through the system and you are seeing blocking on your log readers or distribution agents by the cleanup job, this may be a way to fix it.
In my case this is a SQL Server 2014 distributor, but these procedures haven’t been changed by Microsoft in a good long while, so this should work with all versions.
Denny
2 Responses
Hi, I’ve come across this blog as we regularly get deadlock issues on this job: we have hundreds of distribution agents. Just wondering if 6 months down the line your changes are still ok?
Richard,
Recently we had some strange lock escalation issues with the distributor which required some more drastic changes to the server. But up until then these changes were working perfectly.