During TechEd Europe I got a very scary phone call. A very large table was throwing errors that the value being inserted into the primary key column was overflowing the data type that makes up that column. In this case the data type in question was INT, so we were trying to stick the number 2,147,483,648 into the column and that number just doesn’t fit. The error that we got looked something like this:
System.Data.SqlClient.SqlException: Error 8115, Level 16, State 1, Procedure SomeStoredProcedure, Line 103, Message: Arithmetic overflow error converting IDENTITY to data type int. Uncommittable transaction is detected at the end of the batch. The transaction is rolled back.
Ourshort term solution was quick and easy, to change identity seed of the column from 0 to the lowest possible number, in this case -2,147,483,648 which got us back up and running pretty quickly. This however isn’t a very long term solution for this system. The application is only about 3 or 4 years old, and has been growing very quickly over the last year or so. We estimated based on the last few weeks worth of data that we would run out of negative numbers within about 12 months at the most. We sent an estimate of 9 months to the business when we advised them that the system was back up and running. We also told them that we wanted this fixed within 5-6 months to be save because if we didn’t get this fixed before running out of negative numbers there wouldn’t be any short term fix and that we’d be looking at a multi-day outage to fix the problem.
We couldn’t just rush into a database side fix, as the fix in this case is to change the data type from INT to BIGINT. As the application does use this column in a couple of places the .NET application needed to be reviewed to ensure that anything that was looking for an INT was corrected to handle the BIGINT correctly.
Based on the amount of data within the table (about 300 Gigs) it was decided that taking an outage to make the change in place wasn’t really an option as doing the size change in place would require somewhere around a 5 day outage to remove and rebuild all the non-clustered indexes. To make things a little more complex there is a second table which has a 1=1 relationship with this table, and the second table is even larger (about 800 Gigs), though thankfully the second table doesn’t have any non-clustered indexes.
The solution that was decided on was to move the data from the current table to a table with a BIGINT data type while the application was running. To do this meant that we needed to get all the data copied over to the new table and in sync while the old table was being used. It was decided that the easiest way to do this would be to use triggers. In this case instead of one complex trigger to handle all insert, update and delete operations three separate triggers were used for each of the two tables. First I created two new tables, with the exact same schema as the old tables, with the exception that the new tables used the bigint data type for the primary key instead of the int data type for the primary key and the new table was setup with the ident being the next available positive number. Once that was done the triggers were setup. The insert trigger is pretty basic. Take the data that was just loaded and stick it into the new table.
CREATE TRIGGER t_MyTable1_insert ON dbo.MyTable1
FOR INSERT
AS
SET IDENTITY_INSERT MyTable1_bigint ON
INSERT INTO MyTable1_bigint
(Col1, Col2, Col3, Col4…)
SELECT Col1, Col2, Col3, Col4
FROM inserted
SET IDENTITY_INSERT MyTable1_bigint OFF
GO
The update and delete triggers required a little more logic. The trick with the triggers was that I needed to avoid doing massive implicit data conversions. In order to ensure that SQL was doing what I wanted (which it should be doing anyway, but it made me feel better doing explicit conversions) I explicit conversions into place for the JOIN predicates as shown. The update trigger is shown first, then the delete trigger.
CREATE TRIGGER t_MyTable1_update ON dbo.MyTable1
FOR UPDATE
AS
UPDATE MyTable1_bigint
SET MyTable1_bigint.[Col2] = inserted.[Col2],
MyTable1_bigint.[Col3] = inserted.[Col3],
MyTable1_bigint.[Col4] = inserted.[Col4],
…
FROM inserted
WHERE cast(inserted.Col1 as bigint) = MyTable1_bigint.Col1
GO
CREATE TRIGGER t_MyTable1_delete ON dbo.MyTable1
FOR DELETE
AS
DELETE FROM MyTable1_bigint
WHERE Col1 in (SELECT cast(Col1 as bigint) FROM deleted)
GO
Once these tables were up and running all the new data changes were being loaded into the table. At this point it was just a matter of coping the existing data into the table. There are a few ways that this can be done. In this case I opted for an SSIS package with a single data pump task, and two data transformations within the data pump task with one transformation for each table.
In order to make the load as fast as possible I used the fast load option and loaded 1000 rows at a time. Within the data task if there was an error I redirected the rows to another data pump task which simply dropped the rows into the same table, but this time going row by row. Any failures from that import were simply ignored. While handling failed rows like this is time consuming it is easier than running T-SQL scripts to verify which rows are needed and which rows aren’t needed. SSIS also gives an easy option to ignore the foreign key relationship between the two tables so if the child table gets rows first that isn’t a problem as we know that the parent table will catch up. The SSIS package looked like this:
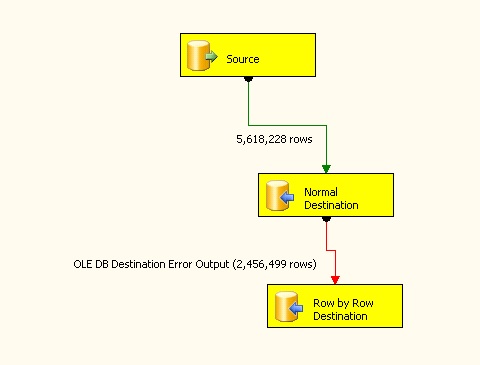
When all is said and done and the data is in sync between the new and old tables, the current tables will be dropped and the new tables will be renamed and put into place so that the application can continue to run without issue, with just a few minutes of downtime.
So why did this happen? When the applications database was being designed the developers didn’t think about how many rows the database was going to get over time, so they didn’t account for needing to support more than 2.1 billion rows over time. If I (or another data architect) had been involved in the project at it’s start this hopefully would have been caught at design time. However when the application was first being designed the company was brand new and didn’t have the funds for a data architect to help with the application design so this problem was missed.
Hopefully you never hit this problem, but if you do this helps you get out of it.
Denny
One Response
Just stumbled on this. We just had to fix the same issue in our environment a few weeks ago. Our scenario was a bit different where we had a very granular partitioned table and we had to rebuild indexes as well.