In my last blog I explained what a columnstore index is, in this blog, we will dive into creating a clustered columnstore index and look at the performance differences the index can make.
Let’s get started.
Using AdventureworksDW2016CTP3 we will work with the FactResellerSalesXL table which has 11.6 million rows in it. The simple query we will use as a demo just selects the ProductKey and returns some aggregations grouping them by the different product keys.
First, we will run the query with no existing columnstore index and only using the current clustered rowstore (normal) index. Note that I turned on SET STATISTICS IO and TIME on. These two SET statements will help us better illustrate the improvements provided by the columnstore index. SET STATISTICS IO displays statistics on the amount of page activity generated by the query. It gives you important details such as page logical reads, physical reads, scans, and lob reads both physical and logical. SET STATISTICS TIME displays the amount of time needed to parse, compile, and execute each statement in the query. The output shows the time in milliseconds for each operation to complete. This allows you to really see, in numbers, the differences.
USE [AdventureworksDW2016CTP3] GO SET STATISTICS IO ON GO SET STATISTICS TIME ON GO SELECT ProductKey, sum(SalesAmount) SalesAmount, sum(OrderQuantity) ct FROM dbo.FactResellerSalesXL GROUP BY ProductKey
Looking at the results below, it completed five scans, 318,076 logical reads, two physical reads and read-aheads 291,341. It also shows us a CPU Time of 8233 milliseconds (ms) and elapse time of 5008 ms. The optimizer choose to scan the existing rowstore clustered index with a cost of 91% and scanned the entire 11.6 million records to return the 395 record result set.


Another thing worth noting is if you hover over the Clustered Index scan you can see that the storage of this index is Row and the Actual Execution Mode is also Row.

Now let’s create the Columnstore index on this table.
Using the GUI right click on indexes and choose New Index then Clustered Columnstore Index.

Under the General table all you need to do is name the index. If there are any objects in the table that is not compatible you will see them listed in the highlighted section below. There are many limitations and exceptions to columnstore indexes such as certain data types like text, ntext and image, and features like sparse columns. To best see the full list of limitations take a look at the docs Microsoft gives us here.

Because of the compression involved, creating a columnstore index can be very CPU resource intensive. To help mitigate that SQL Server gives us an option, under the Options tab, to overwrite the current MaxDop server setting for the parallel build process. This is definitely something you want to consider while creating columnstore index in a production environment. For this example, we will leave as default. On the other hand, if you are building this index during downtime, you should note that columnstore operations scale linearly in performance all the way up to a MaxDOP of 64, and this can help the index build process finish faster at the expense of overall concurrency.
Per docs.microsoft
max_degree_of_parallelism values can be:
· 1 – Suppress parallel plan generation.
· >1 – Restrict the maximum number of processors used in a parallel index operation to the specified number or fewer based on the current system workload. For example, when MAXDOP = 4, the number of processors used is 4 or less.
· 0 (default) – Use the actual number of processors or fewer based on the current system workload.

If you choose to script this out, you will get the below T SQL create statement.
USE [AdventureworksDW2016CTP3] GO CREATE CLUSTERED COLUMNSTORE INDEX [CS_IDX_FactResellerSalesXL] ON [dbo].[FactResellerSalesXL] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) GO
When you run this statement, you will get an error which states the index could not be created because you cannot create more than one clustered index on a table at a time.
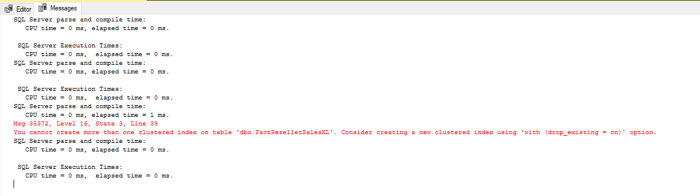
I did this on purpose to illustrate that you can only have one clustered index on a table regardless if you have columnstore or row store indexes on the table. You can change the DROP_EXISTING = ON to remove the row store clustered index and replace it with the columnstore. Moreover, you have the option to create a non-clustered columnstore index as well. This option is typically used when most of the queries against a table return large aggregations, but another subset does a lookup by a specific value. Adding additional non-clustered index will dramatically increase your data loading times for the table.
However, to keep things simple you will note that the AdventureWorksDW216 database also has a table called dbo.FactResellerSalesXL_CCI which already has a clustered columnstore index created. By scripting that out you can see it looks exactly like the one we tried to create. So, let’s use this table which is identical to the FactResellerSalesXL table minus the columnstore index difference.
USE [AdventureworksDW2016CTP3] GO CREATE CLUSTERED COLUMNSTORE INDEX [IndFactResellerSalesXL_CCI] ON [dbo].[FactResellerSalesXL_CCI] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY] GO
Now getting back to the originally query. Let’s run the exact same statement again the columnstore indexed table that again has the 11.6 million rows.
USE AdventureWorksDW2016CTP3; GO SET STATISTICS IO ON GO SET STATISTICS TIME ON GO SELECT ProductKey, sum(SalesAmount) SalesAmount, sum(OrderQuantity) ct FROM dbo.FactResellerSalesXL_CCI GROUP BY ProductKey
Taking a look at the execution plan first. Easily we can see the optimizer went from eight operators to only five operators to complete the transaction and you can see it did an index scan of the clustered columnstore index but this time at a cost of only 36% and read zero of the 11.6 million records.

Next let’s look at the numbers. To see the difference clearer, I have both results for comparison below.
ROW STORE
COLUMNSTORE
The columnstore results have a scan count of four, zero logical reads, zero physical reads, zero read-aheads and 22486 lob read-aheads and took less than a second to run. The reason why these lob activities are in the output, is that SQL Server uses its native lob storage engine for the storage of the columnstore segments. There is also an additional cache for columnstore segments in SQL Server’s main memory, that is separate from the buffer pool. The rowstore index show significant more reads. Lastly note the additional table line, you will see Segments Reads =12. Remember in my last post I discussed how columns are now stored in column segments. This is where we see that the optimizer read those segments.
You can also see that the columnstore indexed results took less time CPU time. The first one was 8233 ms with the elapse time of 5008 ms while the second only took a CPU time 391 ms and elapse time of 442ms. That is a HUGE gain in performance.
Remember earlier that when we used the rowstore index the Actual Execution Mode was Row, here using columnstore, it used Batch mode (boxed in red below). If you recall from my part 1 blog batch mode allows the engine to process multiple rows at one time. This also makes the engine able to process rows extremely fast in some cases, giving two to four times the performance of a single query execution. As you can see our aggregation example happened very quickly because only the row being aggregated is read into memory and using the row groups the engine can batch process the groups of 1 million rows, thus we saw 12 segments read a little over 11.6 million rows.

Now with great power, comes great responsibility. Columnstore indexes are designed for large data warehouse workloads, not normal OLTP workload tables. You want tables that rarely have updates and or deletes. Just because these indexes work really efficiently doesn’t mean you should add them, be sure to research and test before introducing columnstore indexes into your environments.