This is quite possibly my longest blog post title, ever, however it is pretty important for anyone who is building SQL Server configurations using Azure virtual machines. If you aren’t familiar with Azure storage, the max size of an individual disk is 4 TB (and more importantly 7500 IOPs–most workloads will be better served by the 1 TB/5000 IOPs P30 disks), and to get a volume larger than the size of a single disk (and with more IOPs), the admin will use Storage Spaces to create a RAID 0 group (because Azure provides RAID in the infrastructure) and you get the sum of your storage and IOPs. This process is well documented and I’ve done it a number of times or customer workloads. I was building a new availability group for a customer last week, and the process was a little bit different, and failed on me.
Windows Clustering is Aggressive with Your Storage
Note: As I was writing this post, about four different parts of the VM creation process changed in the portal. Welcome to cloud computing boys and girls.
So in this demo–I created a VM and added two disks. I’ll also join the VM to our Active Directory domain. I haven’t added failover clustering yet. From server manager, I can see my primordial storage pool, with the two disks I’ve added.

So, next I’ll add the Failover Clustering feature and build a one node cluster. For this demo, you only need one node–the behavior is same in a single or multi-node configuration. I’ve built a cluster and you will note that there are no disks present in the cluster.
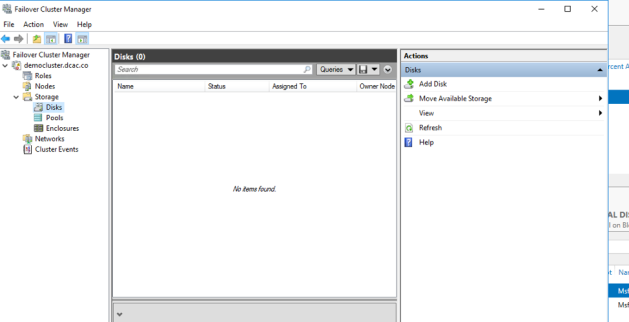
However, if I go back to storage spaces, I still see my primordial pool, but no physical disks, and now I have an error about “Incomplete Communication with Cluster”
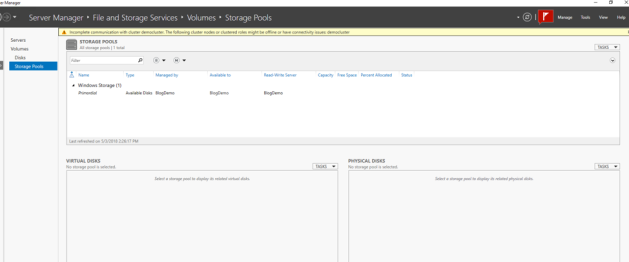
At this point, I am unable to configure a storage pool for my SQL Server data.
I’ve had inconsistent results here–but in no situation have I been able to create a storage pool.
Workaround
This really sucks, but the workaround is the evict the node from the cluster, and then create your storage pool as documented above. That’s kind of gross, so a better workaround is to configure your storage spaces pool, before you add your node to your Windows cluster. I did test the process of adding a new disk to an existing pool, after the server has been clustered and that process works as expected.
Root Cause
My thought (and I haven’t tried to debug this, but I have communicated with Microsoft Windows and SQL teams about it) is that clustering is being too aggressive with the available storage. I tried running some PowerShell to prevent clustering from taking the disks, but I still had the same result. I’ll update this post if I hear anything further from Microsoft.